Atlas AI Cluster
Solutions for your AI Workload
Get to Result Faster with the Atlas AI Cluster
Looking for a fast, powerful system designed from the ground up to optimize large AI datasets? Consider the Silicon Mechanics Atlas AI Cluster™.
This custom-engineered, Linux-based cluster includes best-of-breed technology (including the NVIDIA® HGX™ A100 and AMD EPYC™), configured for fast deployment and powerful results. Best of all? The Atlas AI Cluster can give you GPU-accelerated computing that scales to any size and still provides stronger ROI compared to the equally powerful but more costly NVIDIA® DGX™.
Get More Information
Ideal Use Cases
- Natural Language Processing
- Machine Learning
- Deep Learning
- Predictive Analytics
- Cybersecurity
- Business Intelligence
- Virtual Assistants
- Robotics
Relevant Industries







Pre-Configured for Your AI Workloads
Quick setup
Atlas AI Clusters are pre-configured for AI, reducing time to result even on the largest workloads.Low TCO
Save in the long run with the low total cost of ownership compared to traditional supercomputers.Grows with you
Each cluster is designed to give you seamless, linear scaling as your computing needs grow.Superior performance
Optional 3rd Gen AMD EPYC™, the world’s highest-performing x86 server CPUi.No platform lock-in
Lower initial cost and no platform lock-in compared to the NVIDIA® DGX A100.Blazing fast memory
Includes NVIDIA A100 GPUs, providing world’s fastest memory bandwidth (over 2 TB/s) to run the largest models and datasetsii and GPU partitioning.Resources
Learn More About the Atlas Cluster
Silicon Mechanic engineers were able to achieve so much in a single AI platform by using a building block approach, where computing, storage, and networking components were optimized for specific AI needs.
However, because of the way they are integrated, end users can still request changes for today and scale as needed tomorrow.


How a Building Block Approach Enables AI Optimization
Download this white paper from InsideHPC and get a deep dive on the various modules inside the Silicon Mechanics Atlas AI Cluster and see how it can help you achieve your AI goals.
Download White PaperGPU-Accelerated Compute Node Components
PROCESSOR
2x AMD EPYC 7742 64-core CPUs (128 cores total)
MEMORY
2TB DDR4 system memory
GPU ACCELERATION
4U server with 8x NVIDIA HGX™ A100 GPUs and 640GB GPU memory
STORAGE
- 2x 1.92TB M.2 NVMe storage
- 30TB U.2 NVMe storage
NETWORK INTERFACE
NVIDIA Mellanox® Spectrum® SN2000 GbE HDR switches
POWER
4x 3000W power supplies (3+1)
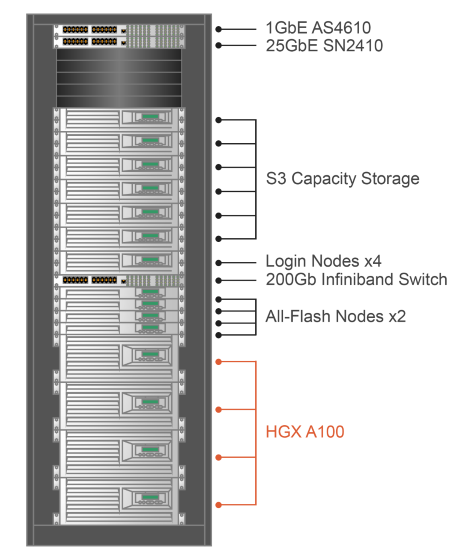
Benchmark Your Performance
Not sure how well the combination of AMD EPYC and NVIDIA HGX A100 will meet your specific workload needs?
The Silicon Mechanics engineering team has set up remote compute modules for secure log in so that you can try both a 4x A100 GPUs (160GB memory) version and an 8x A100 GPUs (320GB memory) version.
Request a Test DriveStorage Components
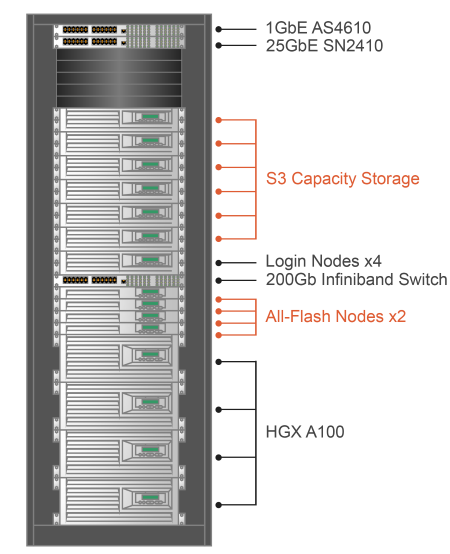
Includes 8 Weka.IO storage nodes + 1 additional Weka.IO node per additional GPU node. Additional optional storage nodes available as needed.
Weka All-Flash Tier
- 4x High-density, all NVMe Flash storage arrays: 1U dual-node storage server with 36x E1.S (EDSFF) NVMe SSDs
- Base configuration starts at 200TB NVMe SSD capacity
- Base configuration scales to 360TB by adding drives, or >360TB by adding storage nodes
- 2x Mellanox 25GbE adapter ConnectX-6 Dx (2x SFP28)
- 2x Mellanox 200Gb/s HDR InfiniBand adapter ConnectX-6 VPI (1x QSFP56)
- 1300W 1+1 Redundant power supplies - 80 PLUS Platinum
S3 Object Storage Capacity Tier
- Node count and drive density based on capacity requirements
Supported Software & AI Frameworks
Includes the Silicon Mechanics AI Stack, Silicon Mechanics’ Scientific Computing Stack, and support for popular frameworks
Expert Included
Our engineers are not only experts in traditional HPC and AI technologies, we also routinely build complex rack-scale solutions with today's newest innovations so that we can design and build the best solution for your unique needs.
Talk to an engineer and see how we can help solve your computing challenges today.